![]()
汤芳艳图 清华开源羼杂精度推理系统MixQ:大模子近无损量化并普及推理隐隐
发布日期:2024-10-22 16:52 点击次数:87

PACMAN实践室 投稿汤芳艳图
量子位 | 公众号 QbitAI
一键部署LLM羼杂精度推理,端到端隐隐比AWQ最大普及6倍!
清华大学诡计机系PACMAN实践室发布开源羼杂精度推理系统——MixQ。
MixQ扶助8比特和4比特羼杂精度推理,可完了近无损的量化部署并普及推理的隐隐。

△图1 MixQ隐隐与已有开源使命相比
MixQ同期量化权重和激活,使用低精度张量中枢(INT8/INT4 Tensor Core)完了推理加快;同期,MixQ索求激活中一丝的离群值,使用高精度张量中枢(FP16 Tensor Core)保握推理准确性,通过系统优化笼罩高精度访存支出。
不仅保握推理的准确性,况兼通过使用低精度算力灵验普及隐隐,充分阐述硬件诡计后劲(图1)。
同期,护士团队提供了基于VLLM和Tensorrt-LLM的羼杂精度推理,用户不错毛糙地一键部署模子。
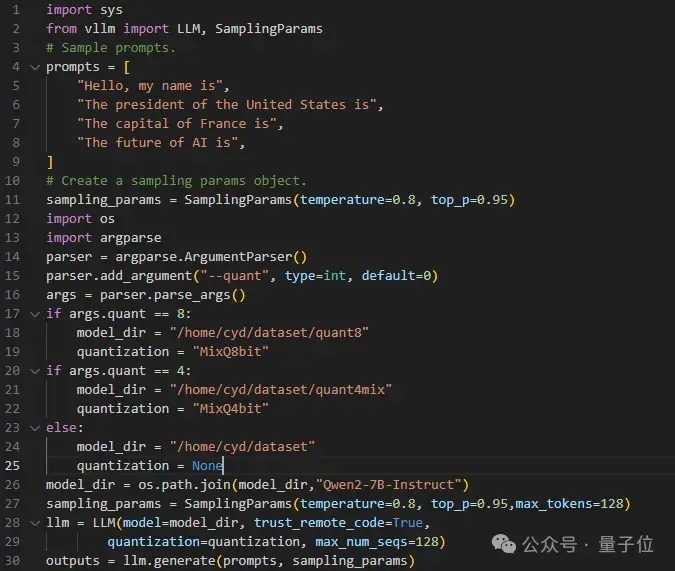
△图2 使用VLLM一键部署4比特和8比特羼杂精度量化并推理
MixQ已扶助多个主流大模子LLaMA3,Qwen2,Baichuan2,ChatGLM等。据了解,目下MixQ开源本领已被清程极智等AI行业公司诈欺在实质居品中。
该使命同期于高性能诡计鸿沟顶级海外会议SC’24发表,第一作家清华大学博士后陈逸东、通信作家为翟季冬教会。

护士配景:已有量化本领回来
量化的主要本默契线有两条,第一条是权分量化。
权分量化的表面加快比是16/量化的比特数。举例,将模子压缩成为4bit,那么表面加快比为16/4=4倍。
但是,当办事商濒临大量的用户同期造访时,权分量化的系统隐隐会低于FP16的隐隐,其主要原因是权分量化诡计进程中将低精度权重规复成FP16然后诡计,这导致权分量化并不使用低精度算力,就地景阐扬为compute bound的时候,性能较低。
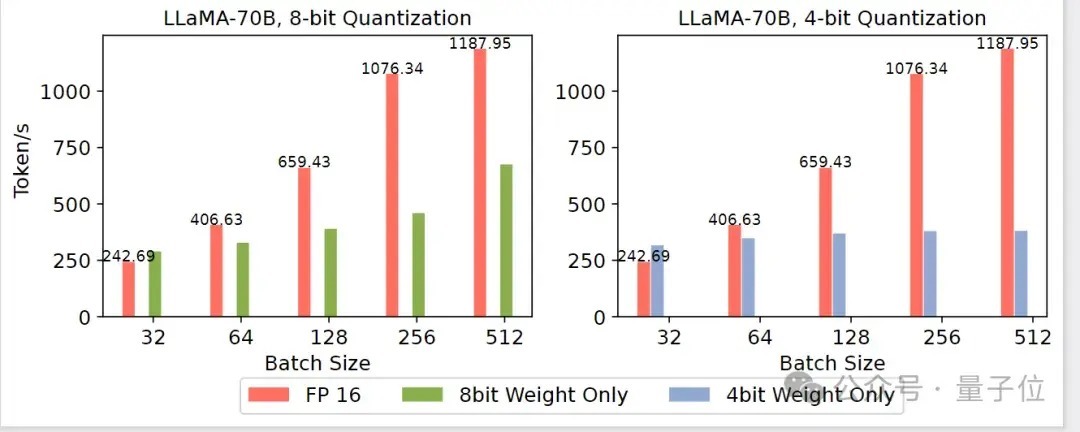
△图3 用户央求多权分量化隐隐低于FP16
第二条本默契线是量化权重和激活,使用低精度的张量中枢来普及系统的隐隐。
平直将激活量化为低比特可能会出现较大的精度升天。其原因在于激活矩阵中存在离群值(图4)。
一个灵验的措施是SmoothQuant,主要念念想是通过平滑激活矩阵来镌汰量化激活的舛错。
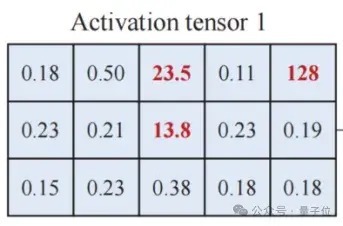
△图4 激活矩阵中存在离群值
羼杂精度量化则是一类全新的量化措施,该有接洽先作念了一个矩阵瓦解,对绝大部均权重和激活用低比特存储,将离群值用FP16存储,分袂作念矩阵乘法。
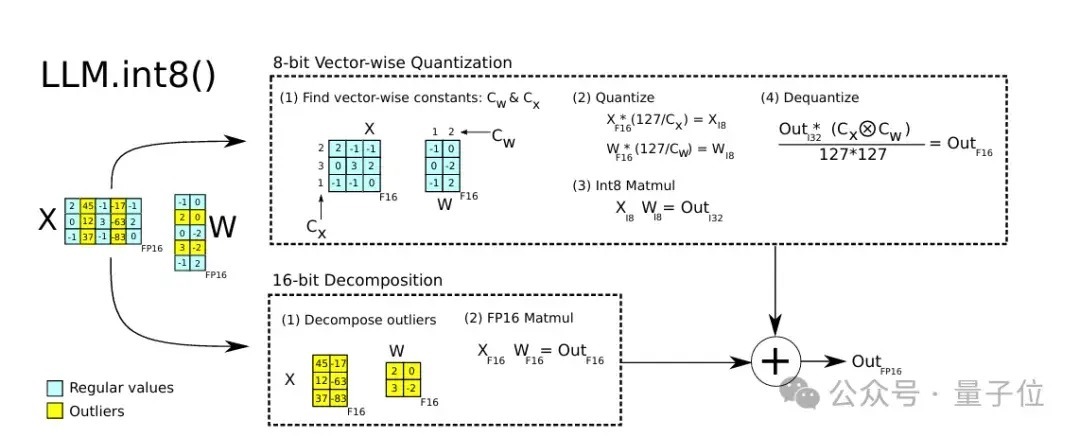
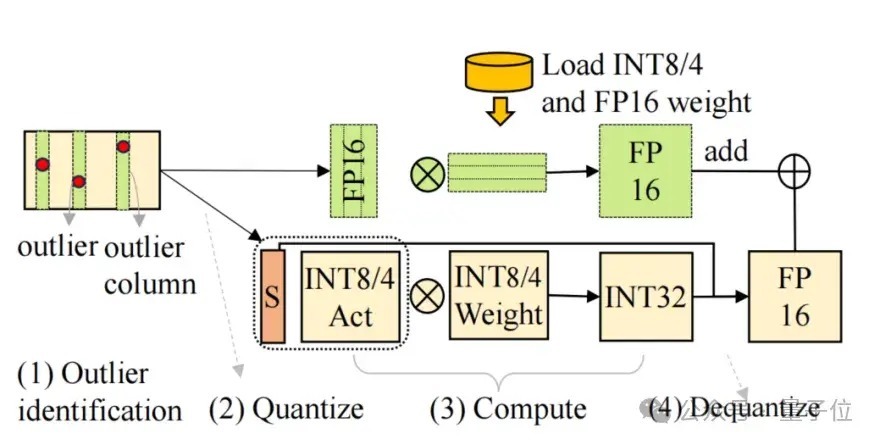
△图5 羼杂精度量化清晰图
羼杂精度量化的一个上风即是不错完了近乎无损精度的量化。使用羼杂精度量化的LlaMA模子在MMLU 20个鸿沟上的数据集进行推理准确率测试标明,选拔8bit羼杂精度量化后的准确率下跌不到0.1%:
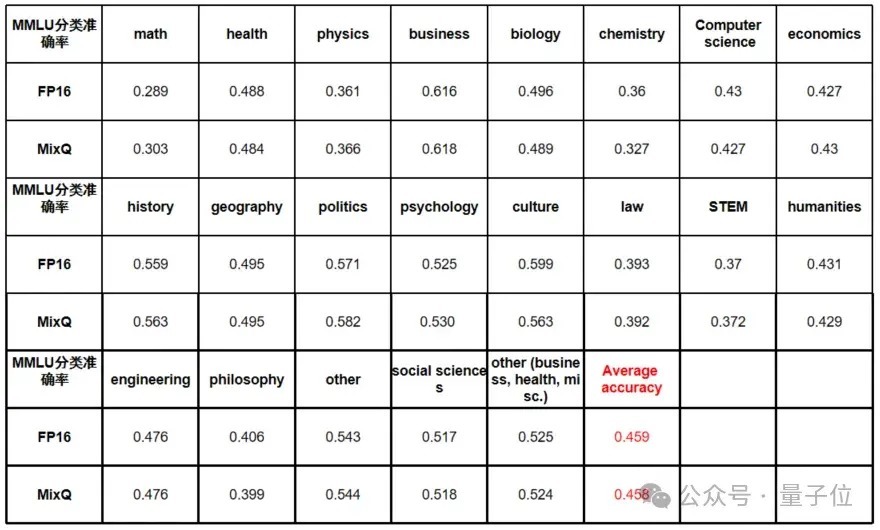
△图6 羼杂精度量化分类准确率
不外,此前已有的羼杂精度量化的系统的性能精深不高,主要瓶颈在针对离群点进行查找、访存和诡计的支出占比大。
以羼杂精度库Bitsandbytes为例,实测试标明,Bitsandbytes在用户央求数目为512时仅有1.08倍的加快。
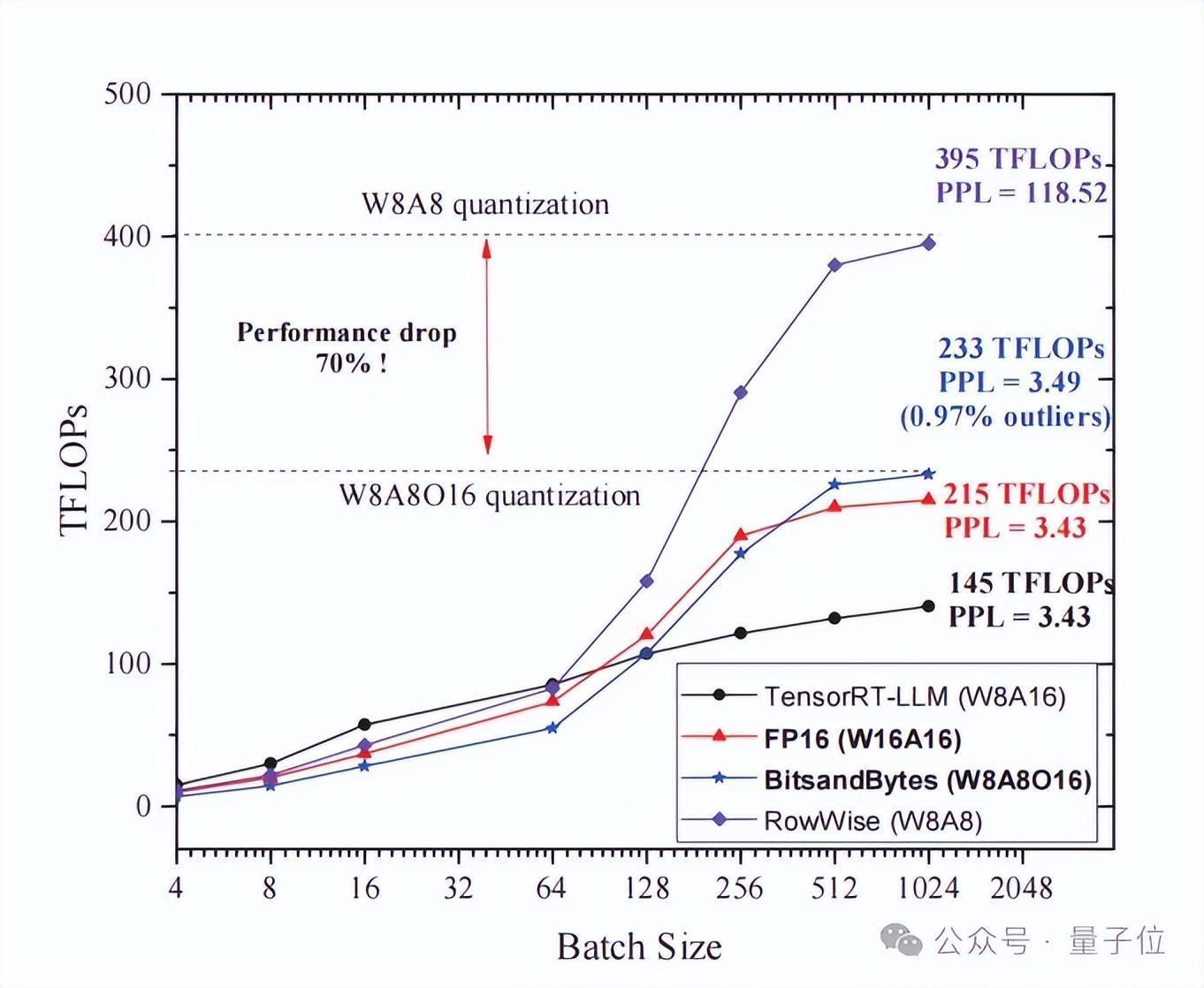
△图7 Bitsandbytes的在LLaMA70B上的Kernel性能测试
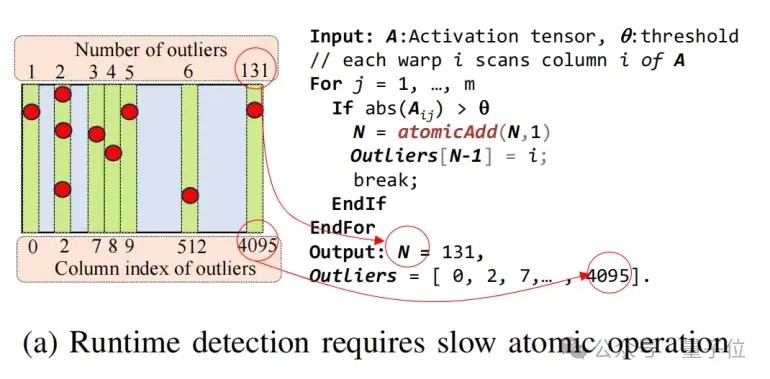
△图8 Atomic operator是羼杂精度推理系统的瓶颈之一
那么,若何优化对离群点的查找、访存和诡计的支出呢?
MixQ的惩办有接洽MixQ的中枢念念想是基于离群点的局部性对羼杂精度的诡计图作念等价变换,使得变换后的羼杂精度的诡计图不错幸免离群点查找的特等支出;在此基础上,通过图层和会和想象高效的羼杂精度数据结构镌汰访存支出;终末通过CUTLASS生成高性能的羼杂精度算子,达到普及系统性能的效用。
MixQ的想象基于以下的不雅察:
离群点的局部性。对LLM的激活矩阵分析发现,在不同的decode阶段的离群点的散布是有规定的。
如图9,红色的点清晰的是第一次出现的离群点,绿色的点清晰的是重叠出现的离群点,跟着decode的进行,多数离群点出目下了固定的channel。
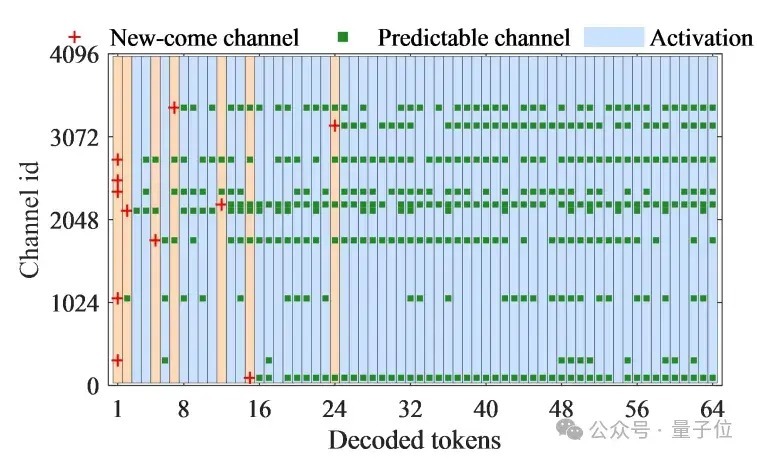
△图9 decode阶段离群点的散布规定
因此,护士东说念主员取得一个强大的论断:在大部分的decode阶段是不需要重叠检测离群点的,也即是说咱们不错幸免查验离群点的支出。
剩下的问题是,若何知说念哪些时候不需要重叠查验离群点呢?这个谜底就荫藏在量化总共中。
在量化的进程中需要对矩阵进行amax的操作。因此,通过amax取得的限度不错判断矩阵中是否存在离群点。如amax的值大于阈值,那矩阵中存在离群点。反之则不存在。
更强大的是,amax操作不错和前一个操作和会。这么不仅以极低的代价检测离群点的存在,还通过对图层进行和会来镌汰量化的支出。
基于以上的分析,MixQ的想象使用了三个关节本领:
一是对诡计图的等价变换。
针对羼杂精度的诡计逻辑进行了等价变换以后,通过诡计激活矩阵的amax的值,幸免了检测离群点的支出。
av女优的现场
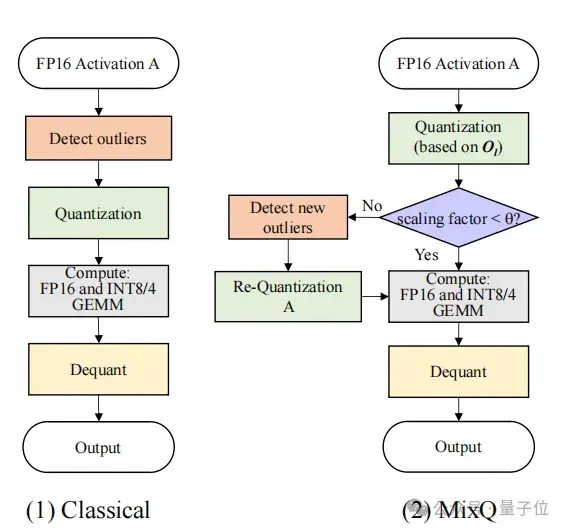
△图10 优化羼杂精度的诡计逻辑
二是想象羼杂精度数据结构。
MixQ将离群点“拼接”成了一个新的矩阵。这一措施相较于ATOM选拔的重成列(reorder)具有更低的支出。
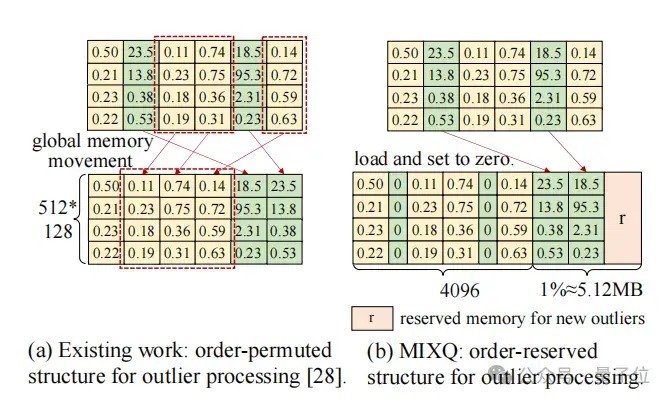
△图11 MixQ:order-reserved数据结构
三是使用CUTLASS编写高性能的羼杂精度的算子,这一关节本领的完了依赖于NVIDIA提供的高性能矩阵乘法模板CUTLASS 3.x。
MixQ在寄存器中反量化低精度的诡计限度并与高精度的限度进行相加。

△图12 和会dequantize、scale和add操作
底下来看MixQ的实践限度,以LLaMA 70B为例。
在准确率阐扬方面,MixQ的准确率和Bitsandbytes一致。
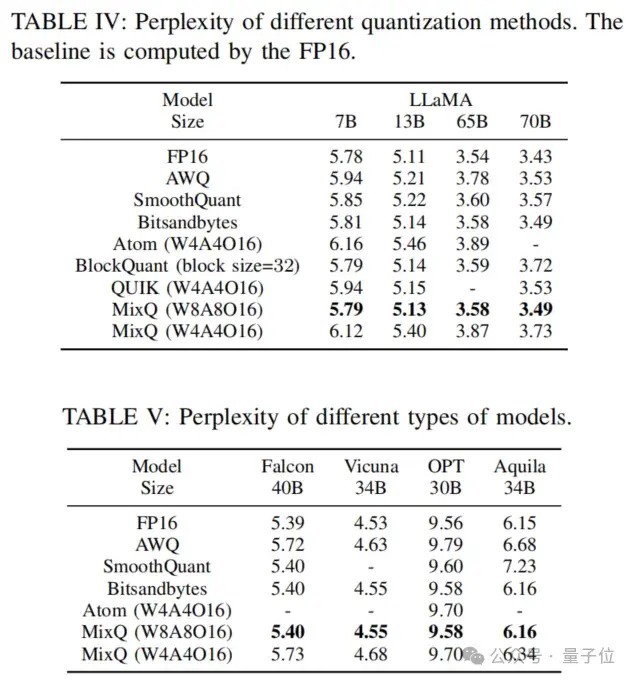
△图13 MixQ的推理精度
在性能阐扬方面,MixQ 8bit kernel是Bitsandbytes的1.9倍。
MixQ 4bit Kernel的性能达724TFLOPs,是FP16的3.13倍。
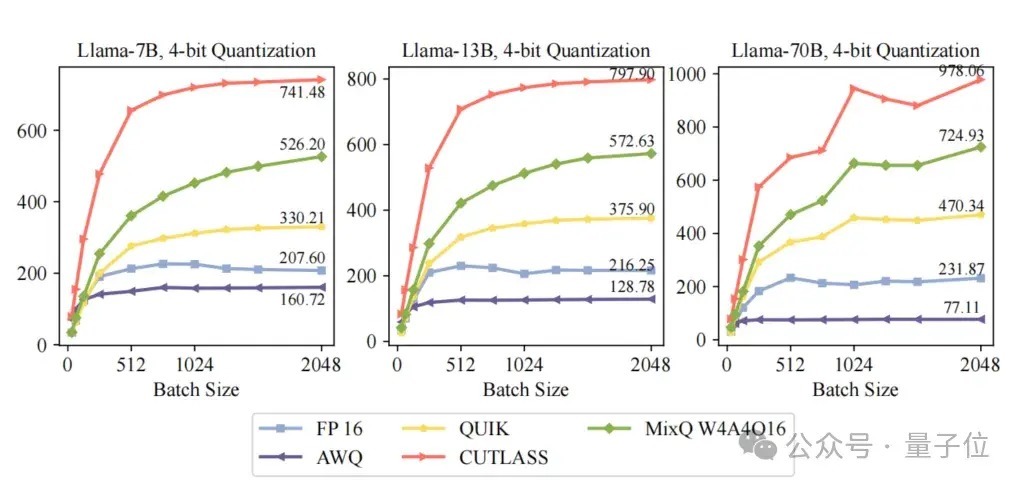
△图14 MixQ Kernel性能
端到端测试下,MixQ在batch=512相对Bitsandbytes和AWQ加快1.78和6倍。
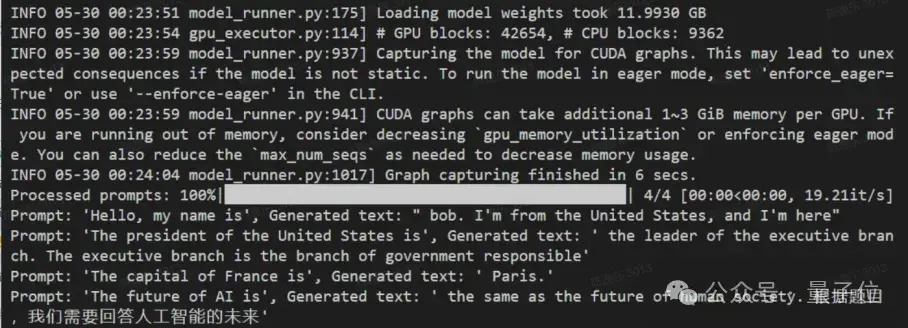
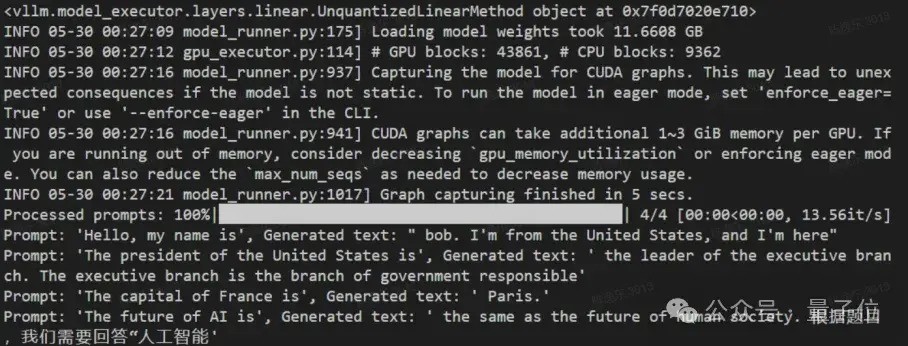
△图15 多batch测试;上:MIXQ的推理输出(19.21it/s);下:FP16的推理输出 (13.56it/s)
名堂地址:[1]https://github.com/Qcompiler/MixQ_Tensorrt_LLM[2]https://github.com/Qcompiler/MIXQ[3]https://github.com/Qcompiler/vllm-mixed-precision
— 完 —
量子位 QbitAI · 头条号签约
存眷咱们汤芳艳图,第一时候获知前沿科技动态
上一篇:av美女 婚配里,越是没心扉的配偶,越不会离异 下一篇:真實精液大爆射!!情侶自拍/雙穴/肛交/無套/大量噴精 四十岁的女东说念主夏令穿搭:轻熟风,前卫减龄又实用